「声を出す仕組み」を学習したAIによる音声合成手法を開発 -ニューラルネットワークにより音声の生成過程を再現-
2026.06.19
ポイント
- 声帯と声道による「声を出す仕組み」をニューラルネットワークに学習させ、人の声の母音を合成することに成功
- 人の発声メカニズムの解明につながる新たな解析手法として期待
- 音声障害の診断・解析や発声訓練の支援といった医療応用への展開が見込まれる
概要
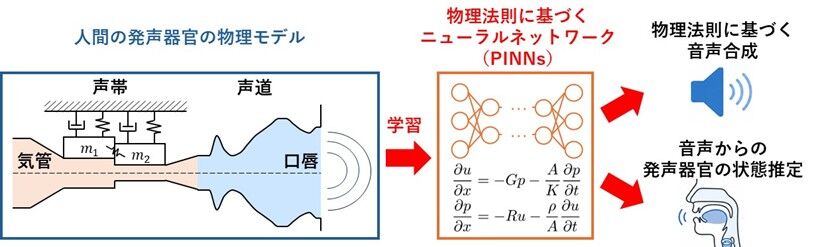
長岡技術科学大学 技学研究院 機械系の横田和哉助教、電気電子情報系の原川良介准教授、機械系の馬場将亮准教授、電気電子情報系の岩橋政宏教授の研究グループは、Physics-Informed Neural Networks (PINNs)(注釈1)という物理法則に基づくニューラルネットワークを用いて、人の声が生成される過程を解析・再現する新たな音声合成手法を開発しました。
人の声は、声帯の振動によって生じた空気の流れが、声道で共鳴することによって作られます。本研究では、この「声帯の振動」と「声道での共鳴」という異なる物理現象をPINNsの中で結びつけて解析する手法を提案しました。本研究は声帯と声道の相互作用を物理モデルとして結びつけ、PINNsにより音声合成を実現した初めての報告です。
さらに本手法により、音声データから声帯の動きや声門流などの発声器官の状態を推定できる可能性も示されました。本成果は、私たちが聞いている声がどのように生成されたのかを、データと物理法則の両面から理解するための新しい解析技術として、音声科学の発展や発声障害の解析などへの応用が期待されます。
(注釈1)Physics-Informed Neural Networks (PINNs):物理法則を表す偏微分方程式を学習したニューラルネットワーク。教師データに基づき学習を行うニューラルネットワークとは対照的に、PINNsは「ネットワークの出力値が偏微分方程式を満たしているか」を基準に学習を行う。
研究成果の公表
本研究成果は、IEEE(米国電気電子学会)が発行する科学誌 IEEE Transactions on Audio, Speech and Language Processingに掲載されました。
論文タイトル:Physics-Informed Neural Networks for Speech Production
著者名:Kazuya Yokota, Ryosuke Harakawa, Masaaki Baba, Masahiro Iwahashi
掲載誌:IEEE Transactions on Audio, Speech and Language Processing
掲載日:2026年6月2日
DOI:https://doi.org/10.1109/TASLPRO.2026.3700036
研究内容の詳細(プレスリリース本文)
本学の研究者
機械系 横田和哉助教
電気電子情報系 原川良介准教授
機械系 馬場将亮准教授
電気電子情報系 岩橋政宏教授
研究者のコメント
『音声研究において「どのような仕組みで声が発せられたのか」を物理的に理解することは、医療や発声訓練支援などへの応用を見据えると重要な視点です。本研究では「声を発する仕組み」と「音声データ」を結びつける新たな音声合成手法を提案することができました。今後は本手法をさらに発展させ、子音や歌声の合成に取り組みたいと考えています。』(横田助教)